In this paper, the authors present a system for generating videos of a talking heard, using a still image of a person and an audio clip containing speech. As per the authors this is the first paper that achieves this without any handcrafted features or post-processing of the output. This is achieved using a temporal GAN with 2 discriminators.




An L1 reconstruction loss is used on the lower half of the facial image to improve synchronization of the mouth movements. The reason for it being applied only on the lower half is because it discourages the generation of facial expressions.

Finally the model is trained to obtain a generator that optimizes the below equation

Novelties in this paper
- Talking head video generated from still image and speech audio without any subject dependency. Also no handcrafted audio or visual features are used for training and no post-processing of the output (generate facial features from learned metrics).
- The model captures the dynamics of the entire face producing natural facial expressions such as eyebrow raises, frowns and blinks. This is due to the Recurrent Neural Network (RNN) based generator and sequence discriminator.
- Ablation study to quantify the effect of each component in the system. Image quality is measured using
Model Architecture
The model consists of a generator network and 2 discriminator networks. The discriminators evaluate the output of the generator (the generated sequence) from two different perspectives. The effectiveness of the generator is directly proportional to the ability of the discriminator to identify real sequences from fake ones. This because GANs are based on a zero-sum non-cooperative game. So two parties are compete where your opponent wants to maximize its actions and your actions are to minimize them. To get a better understanding of GANs check here and here.
Given below (borrowed from the paper) is the overall architecture of the model.

Generator
The generator used here is an RNN based generator. This is important as it allows us to synthesize videos frame-by-frame, which is necessary for real time applications. The generator has 3 sub networks; 1. Identity Encoder, 2. Context Encoder and 3. Frame Decoder

The Identity Encoder learns the speakers facial features. It is encoded to a 50 dimensional vector using a 6 layer CNN.
The second network, the Context Encoder encodes the audio frames into a 256 dimensional vector. This comprises of 1D convolutions and a 2 layer Gated Recurrent Unit (GRU). The RNN functionality of the generator is introduced in this network.
The third component, the Frame Decoder takes the output from the previous 2 networks along with a 10 dimensional vector obtained from a Noise Generator (1 layer GRU with input as Gaussian noise) and produces video frames. The latent representation of the image and the audio is combined to produce the video frames. A U-Net architecture is used with skip connections between the Identity Encoder and the Frame Decoder to help preserve the identity of the subject.
Discriminators
The architecture uses 2 discriminators. The Frame Discriminator ensures a high quality reconstruction of the speakers' face in the video. The Sequence Discriminator ensures that the generated frames form a cohesive video without glitches or abnormal frame changes. It also makes sure that natural facial movements are generated and the video is synchronized with the audio.
Frame Discriminator
The Frame Discriminator is a 6-layer CNN that determines whether a frame is real or not. Adversarial
training with this discriminator ensures that the generated frames are realistic. The original still frame
is given as a conditional input to the network. This enforces the person’s identity on the frame.
Sequence Discriminator
The Sequence Discriminator presented distinguishes between real and synthetic videos. The
discriminator receives a frame at every time step, which is encoded using a CNN and then fed into a
2-layer GRU. A small (2-layer) classifier is used at the end of the sequence to determine if the sequence is real or not. The audio is added as a conditional input to the network, allowing this discriminator to classify speech-video pairs

Training the Model
The loss of the GAN (see about GAN loss here) is a combination of the losses associated with each discriminator.

An L1 reconstruction loss is used on the lower half of the facial image to improve synchronization of the mouth movements. The reason for it being applied only on the lower half is because it discourages the generation of facial expressions.

Finally the model is trained to obtain a generator that optimizes the below equation

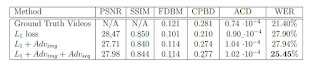
Ablation Study

- L1 loss achieves slightly better PSNR and SSIM results. (Expected as it does not generate spontaneous expressions, which are penalized by these metrics)
- Adversarial loss minimizes the blurriness of the images. This is indicated by the higher FDBM and CPBD results
- Sequence discriminator resulted in achieving a lower word error rate (WER).
Comments
Post a Comment